
I recently was asked to build a predictive text application (a la Swiftkey) as part of the capstone project for the Johns Hopkins data science course. It was my second project involving natural language processing (NLP) in the past few months; I also built a small language prediction tool as the capstone for a machine learning workshop I attended.
The goal of my first NLP project was to learn more about model selection and implementing a model as part of a web application framework. As a result, much of the “up front” work was addressed: several Wikipedia pages were scraped in different languages, labeled, and then passed through a vectorizer to create 3-char tokens.
This project, the predictive text application, would require significantly more work, for two reasons: (1) we were starting with a raw corpus, and (2) predictive activities (ie, inferring the “future”) are harder than descriptive activities (ie, inferring “characteristics”). I ony focused on predictions of the English language.
In this post, I’ll describe the process of building the application with an eye towards how I might approach the problem if done again in the future.
##Exploring the Corpus
In the exercise, we used the HC Corpora to develop a predictive text model. The HC Corpora is web-scraped text from a guy named Hans Christensen (thus, HC) in the form of blogs, twitter, and news sources. He has more than 2.5 billion words in 67 languages, which is amazing.
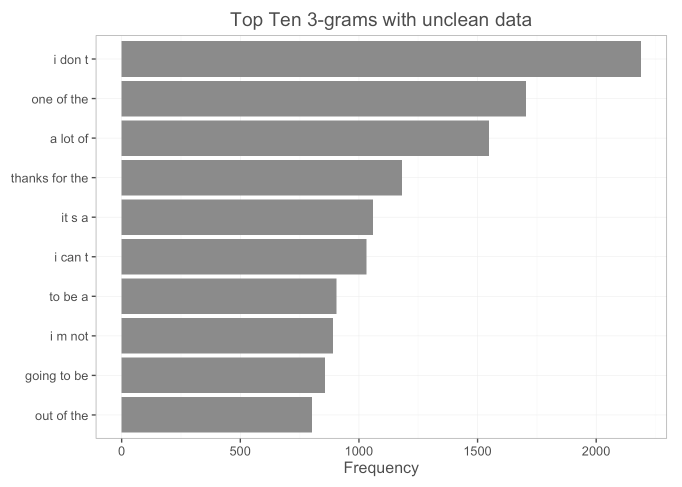
To start, I wanted to get a sense of what common n-grams would look like without cleaning. I also wanted to get a sense of what the n-grams would look like if I took out “stop words.” Stop words are common fillers like “of”, “a”, or “the”. I saved both of these experiments as .csv files to demonstrate why a cleaning of the data was necessary, and why I left stop words in. Removing stop words resulted in a frequency that likely would not be helpful for users. For example, the 2nd most common 3-gram without stopwords was “happy mothers day”. I sampled 2% of the full Corpora.
Using the common cleaning functions from the tm package in R, I created a master function for cleaning the corpora. Note that the order of the functions is important. For example, the list of profanities are all in lowercase. Therefore, if ‘tolower’ did not come earlier - I would have left in some profanities. Per the recommendation of the RWeka documentation, I also created functions for the different multi-word tokens that I will be creating.
clean_text <- function(text){# Helper function to preprocess corpustext <- tm_map(text, content_transformer(tolower))text <- tm_map(text, removeNumbers)text <- tm_map(text, removePunctuation)text <- tm_map(text, stripWhitespace)text <- tm_map(text, removeWords, stopwords("english"))text <- tm_map(text, removeWords, profanities)return(text)}
BiTokens <- function(x) {RWeka::NGramTokenizer(x, RWeka::Weka_control(min = 2, max = 2))}TriTokens <- function(x) {RWeka::NGramTokenizer(x, RWeka::Weka_control(min = 3, max = 3))}QuadTokens <- function(x) {RWeka::NGramTokenizer(x, RWeka::Weka_control(min = 4, max = 4))}
For some reason, RWeka has trouble parallelizing the different cores on my OSx. I could only get the functions to work if I specifically stated that I will only use one core. Here, I am creating a 2-, 3-, and 4-gram model. The TDM function creates a very sparse matrix, which I collapse, and then turn into sorted dataframes by frequency.
tdm3a <- TermDocumentMatrix(clean_join, control=list(tokenize=TriTokens))tdm3 <- removeSparseTerms(tdm3a, 0.9999)freq3 <- sort(row_sums(tdm3, na.rm = T), decreasing=TRUE)freq_frame3 <- data.frame(word=names(freq3), freq=freq3)
Tokenizing is a computationally-heavy exercise - since I was only using one core, it would take me more than an hour just to parse 2% of the Corpora once (say, for a 3-gram instead of a 4-gram). As a result, I took shortcuts in developing my database - I would have wanted to ensure that I knew how much of the overall vocabulary was covering, and I chose not to calculate this. There must be a threshold for which additional information is low utility - probably more extreme than Pareto rules (ie, 80% of info covered in 20% of Corpora) - but I am sure that I did not hit that threshold.
##Building the Model:
To predict text, I wrote a function that represented a stupid backoff model. This model works by first matching a database of different “n-grams” to the provided text, and then assigning strengths to different outcomes based on how the match takes place. For example, take the phrase, “The quick brown fox jumps over the lazy dog.” If I have typed “The quick brown fox jumps…” my backoff model would first look at “brown fox jumps” (a 3-gram), then “fox jumps” (a 2-gram), then “jumps” (a 1-gram) - if a match occurs in those three lookups, that answer is provided.
As opposed to my approach of taking the “strongest match,” the backoff model applies a discount for each recursive step (traditionally 0.4) and then provides a “score” for each potential match. The highest score at the end of the process results in the prediction.
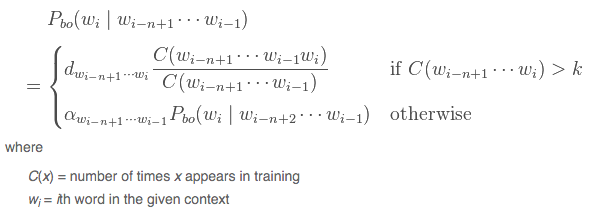
The project was coded in R - as a result I used the Shiny framework and hosted the application on Shinyapps.
##So, what did I learn?
- Stanford has a lot of good research on different ‘smoothing methods’ (eg, Jelinek-Mercer, Witten-Bell, Good Turing, and Kneser-Ney). Descriptions of those methods can be found here: Stanford NLP Smoothing Tutorial. Many academics have worked to tackle this problem in the last 15-20 years, and there is sufficient literature as a basis for developing a model.
- There should be triggers for when to use ‘stopwords’ and when to refrain. Words like ‘to’, ‘of’, and ‘the’ don’t necessarily convey the context of what someone may be trying to communicate - at the same time, they are used frequently enough that they should be included in a predictive model.
- Database structure / type provides a lot of flexibility for fast recall. For example, Redis or MongoDB. This was a great attempt to try different database structures for this project. These are tools that are commonly used in my day job, and I would have loved a bit more time to play around with them. Especially how the use of the database might influence use of memory, speed of access, and the required structure for how the data is stored.
Two things I would have loved to explore are:
- Dynamic improvement of the model. How can user inputs (and the knowledge that a prediction is correct or incorrect) help develop a model that greatly increases in accuracy over time?
- Refining model accuracy. I refrained from constructing a holdout set, as I did not have enough free time to build a separate model. For example, does one separate the holdout Corpora by lines and then choose both the random placement of a word and a random set of preceding words for matching? I would love to learn more about best practices.