
Note: If you would like to skip directly to my Jupyter notebook of this exercise, you can find it at this link.
Project Summary
This project is the capstone for the “Introduction to Machine Learning” course in the Udacity Machine Learning Engineering nanodegree. It involves using the “Enron corpus”—a body of information that was made publicly available following the Enron scandal in the early 2000s. It has all salary information and email communications. It is rare, as most companies keep these communications private. For CS folks, it is particularly valuable—it is a dataset that reveals common networks, patterns, and communications. This is a useful basis for developing and testing new models about how people interact in the workplace.
The goal of project is to use a dataset built from the corpus to create a model that identifies “Persons of Interest” (POIs). A POI is someone whom we believe is a strong candidate for having committed fraudulent activities—for example, Jeffrey Skilling and Kenneth Lay. The dataset includes characteristics about the different individuals at Enron—for example, their known interactions with POIs (how many emails did they send or receive), the portion of their total compensation that was a bonus, etc. Doing some cursory analysis, we have 21 characteristics/columns we could use as “features” in our model. There are 146 individuals in the dataset, of whom 128 are NOT POIs, and 18 are POIs.

The model we are trying to create is an algorithm that will comb the dataset to predict the probability of whether an individual is a POI. Therefore, it is important that we build this algorithm with accurate underlying data. It is most likely that we will not need all 21 columns as “features” in the model, as some will have more predictive capabilities than others, and some may have no predictive capabilities at all. Finally, we may want to create new columns using outside data, or the provided dataset. We would do this if we expect the new columns to be more predictive of POIs than the information we currently have in its existing representation. Here are a few changes I made:
- I threw away the “email_address” field as there isn’t meaningful information between the different values to help us identify a POI.
- I threw away the ‘TRAVEL AGENCY IN THE PARK’ and ‘TOTAL’ rows as outliers.
- I created several new “ratio” fields: the percentage of emails to or from a POI, the percentage of compensation that came in bonus, salary, and restricted stock.
Feature Selection and Tuning
The NaN values in the dataset are a blend of string and nan values. I converted all NaN values to a numpy nan (np.nan) value, and then converted the values to an outlier value (I used -0.42, which is close to (but not quite) the “Answer to the Ultimate Question of Life, the Universe, and Everything.” This allows the dataframe to be processed by classification algorithms that can’t take N/A values, such as Random Forest.
I ran a Random Forest classification quickly to see what my preliminary values were—the answer was not very good. I had “mild” predictive capabilities for people who are NOT POIs, and 0% accuracy/recall/precision for predicting POIs. Part of the reason for this is the imbalance between the two classes (noted earlier, ~85% of the list are not POIs) and the model is trying to predict for the larger class. Fortunately, my colleague Tom Fawcett has written about this (see: Learning from Unbalanced Classes). I began building ROC curves and precision-recall curves to understand performance for different tuning parameters.
To determine the right features and tuning parameters, I built a Pipeline using SelectKBest and GridSearchCV together. The pipeline applies the first step by choosing the best k features and transforms the input data to have only these features. After transformation, this is then fit with different estimators. GridSearchCV helps to tune the “number of features to be selected” and the hyperparameter of the estimator, by selecting the parameters that give the best score on validation data.
Sample code for testing SVMs:
kbest = SelectKBest(f_classif)pipeline = Pipeline([('kbest', kbest), ('svm', SVC())])grid_search_svm = GridSearchCV(pipeline, {'kbest__k': [1,2,3,4], 'svm__C': [1, 2, 3, 4], 'svm__kernel': ['linear', 'poly', 'rbf', 'sigmoid'] })grid_search_svm.fit(features.values, labels['poi'].values)labels_pred_svm = grid_search_svm.predict(features_test)
print classification_report(labels_test, labels_pred_svm)print confusion_matrix(labels_test, labels_pred_svm)print grid_search_svm.best_params_print plot_ROC_curve(grid_search_svm, features.values, labels['poi'].values)print plot_PR_curve(grid_search_svm, features.values, labels['poi'].values)
Selecting an Algorithm and Performance
I tested 3 different types of algorithms on the dataset with the pipeline method described above:
- Decision Trees: A decision tree can be thought of as a flowchart that classifies samples based on feature performance. They are very useful in practice as it is easy to determine provenance—I can articulate how and why an algorithm makes a decision. This is helpful in industries like financial services, in which there are regulations against favoring or biasing against specific groups. The performance for POI prediction can be found below:

- Random Forests: A “random forest” is an ensemble model of different decision trees. Roughly speaking, random forests create several decision trees and then “blend” their results to create a newly predicted outcome. When it comes to accuracy, they are very useful in practice. At the same time, there is a greater challenge in understanding “how” predictions are made. Also, since multiple trees are created and blended, there is often a significant runtime associated with Random Forests, which needs to be accounted for in data products and analytic workflows. The performance for POI prediction can be found below:

- Gaussian NB: Naive Bayes classifiers treat different features as independent of one another. For example, a fruit may be considered to be an apple if it is red, round, and about 10 cm in diameter. A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of any possible correlations between the color, roundness, and diameter features. It has been found useful in text retrieval and medical diagnoses. The performance for POI prediction can be found below:

These calculations are derived from each model’s confusion matrix, which is a table outlining how different predictions performed against a holdout set of data with known labels. If we treat the predictions as probabilities instead of hard labels (for example, an individual is “54% likely” to be a POI as opposed to only 0% or 100%), we can create an ROC chart as a metric for performance: an explanation of how to use ROC curves can be found here. Below is the ROC chart for Decision Trees:
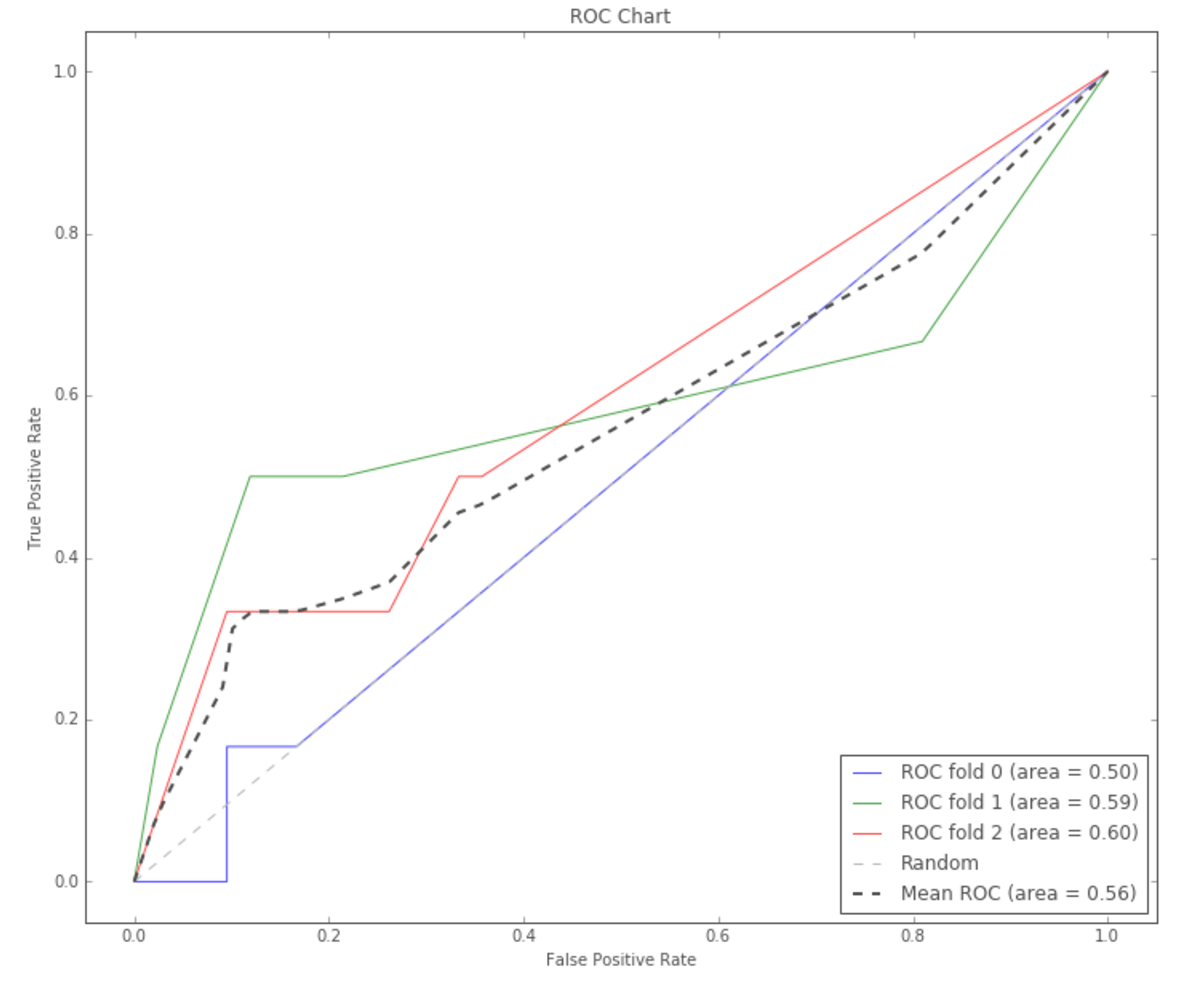
The code I used split the data into 3 “folds”, each of which has different performance—the “mean ROC” is the final measure when deciding the performance of the algorithm. The greater the area indicates stronger predictiveness. There is no absolute threshold for determining good performance—one needs to consider the context surrounding the decision being made. I found that Decision Trees performed the best, as measured by Precision, Recall, and F1 Score.
- Precision is a measure of the number of identified True Positives divided by the total number of Positive test results (including False Positives). FPs are known as Type I Error.
- Recall is the number of identified True Positives divided by the total number of actual Positive samples (including False Negatives). FNs are known as Type II Error.
- A F1 Score is a measure of accuracy, calculated as the harmonic mean of Precision and Recall.
When looking at these scores, I was more focused on the ability to predict “1s” than the overall measures. The value 1 represents a POI. Since the data is skewed towards non-POIs (80%+ of the set), the overall numbers give the impression that the models are more highly predictive than what would be representative of their intended use. Similarly, since the goal of the activity is to identify POIs, we might be comfortable with a lower Precision measurement (increased FPs) if it provides a higher Recall (minimized FNs). Similar biases are present in medical testing.
As an important note, all of my measurements regarding performance are calculated using a “holdout” set or a “fold” that is independent of the data upon which the model is constructed. This is referred to as “validation.” Validation is important because we are trying to generate models that have inference—some predictive capability—on a general population. We want to make sure that our models perform more effectively (much more effectively) than random chance.
To do this, we use a set of data that the model has never seen and may not be entirely representative of the distribution of data upon which the model was constructed. Articulating the model’s performance using these metrics helps ensure that we are not “overfitting” the data—models that are highly predictive of the datasets on which they were trained, but perform poorly in general practice. Here is a great article from IBM Research on preserving validity in analysis.
Conclusion
This was a fun project that helped hammer home some of the key concepts of data preparation and model selection. Much of my prior training in data science was done in R, and I wanted a guided introduction to scikit-learn, numpy, and pandas. It is amazing how transferable the approach and libraries are for the two languages—at the same time, there are funny anachronisms for how scikit-learn takes data from pandas dataframes vs. numpy arrays.