###What was the assignment?
This was by far my favorite assignment in the projects I’ve been doing over the past few months. The goal was to use 20-instance Hadoop cluster on AWS to run Pig queries on a ~0.5TB dataset.
We used the billion triple dataset, which is designed to model the Semantic Web. It is stored and provided by UW; There were 317 2GB files in the billion triple dataset when it was downloaded. The files were uploaded them to Amazon’s Web Services in S3: there were some errors, and only 251 uploaded correctly, for a total of about 550 GB of data.
Also from the project description:
“This graph is similar in size to the web graph. As part of this assignment, we will compute the out-degree of each node in the graph. The out-degree of a node is the number of edges coming out of the node. This is an important property. If a graph is random, the out-degree of nodes will follow an exponential distribution (i.e., the number of nodes with degree d should be exp(- c*d) for some constant c). We will find the distribution of node out-degrees to follow a power law (1/d^k for some constant k and it will look roughly like a straight-line on a graph with logarithmic scales on both the x and y axes) instead of an exponential distribution. If you look at Figures 2 and 3 in this paper, you will find that the degrees of web pages on the web, in general, follow a similar power law distribution. This is very interesting because it means that the Web and the semantic Web cannot be modeled as random graphs. They need a different theoretical model.”
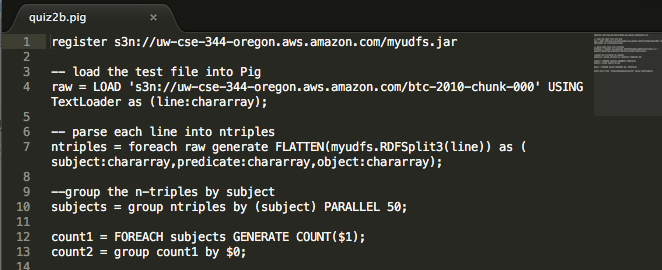
###How does this get done? There were a few steps to finishing this exercise on AWS. First, my website is hosted through S3, so I had some experience with the console and setting up keys. It was straightforward (but still amazingly fun) to set up a Hadoop cluster and know that I am managing servers somewhere in Oregon. After getting my Key and setting up the Cluster, I could begin to run Pig interactively:
$ ssh -o "ServerAliveInterval 10" -i </path/to/saved/keypair/file.pem>hadoop@<master.public-dns-name.amazonaws.com>

Then, to visualize / monitor my jobs taking place, I needed to do some troubleshooting. I ended up using a SOCKS proxy, and my browser. This allowed me to set up a tunnel to a pre-specified port and see my jobs taking place. I could also read the output and summaries of any queries from the terminal itself.
Once we are doing queries, we practice with a test file on a small, 1-node cluster. Once we feel like the histogram code is correct, we then compute for on the entire 0.5TB dataset. Use as many nodes as you like up to 19 small nodes. It was fun / bittersweet seeing this number - I didn’t realize that 20 was the maximum number of servers that can be turned on in a region without requiring authorization. When I originally set up my website, I accidentally made my personal S3 key public, and within 12 hours someone had turned on 120 instances in my name (20 servers each in 6 different regions). Anyway, here is the code: notice its similarity to SQL, with some modifications on the keying.