
Over the past few months, I did the Johns Hopkins Data Science course on Coursera - a 10-course specialization that culminates in a capstone project for a certificate. The courses provide a crash instruction for doing data science in R: early courses focus on the R programming syntax, cleaning data, reproducibility, and performing exploratory analysis. This foundation allows for lessons in statistics, regression, and building data products using Shiny, which is a web application framework for R.
For folks that might be thinking about doing the program, I wanted to share a bit of what a participant can expect to learn, some pros and cons, and things to consider when determining if it is right for you.
##Overview of Course
To start, I would probably not recommend taking all of the courses. Unless you want to pay for the certificate (which I did, but is not necessary) - the utility of the courses are highly variable. I’ll describe each course a bit more below, but the TL;DR version is R Programming, Exploratory Data Analysis and Regression Models are the winning classes to take here.
Regarding reproducibility and statistics: The concept of reproducibility in data analysis is hugely important; I think it is better articulated elsewhere. I would recommend Bill Howe’s lectures on reproducible research. Not only is it important to understand the underlying inputs to a given model, statistical performance tends to change over time (e.g., findings that are surprising to be statistically significant tend to trend towards the mean as a data set grows). Reproducibility allows for confidence in a model’s given performance and makes it easier for these models to be updated over time. The statistics course tries to pack a few months into a few weeks and ends up putting an uncharacteristic strain on the student. It would be better to go slower and take a bit more time with the concepts elsewhere.
- Data Scientist’s Toolbox: This course asks users to download RStudio and set up a Github account - it really is not more than that.
- R Programming: In one month, you can go from knowing nothing about R to writing your own functions. Also, StackOverflow becomes your best friend. Highly recommended. A few weeks ago, I opened an .xls file in Excel and immediately closed it because I found it easier to understand the data in R. That is thanks to this class.
- Getting and Cleaning Data: This is a good course for understanding the data science pipeline - taking data in its raw form, writing code to get it in a structure for analysis, and then writing code to perform analysis. It also walks through the benefit of having a robust README and Codebook.
- Exploratory Data Analysis: EDA is a set of practices for developing hypotheses around the value data may hold. One particularly useful tool is visualization; this course introduces the ggplot2 package, which was developed by Hadley Wickham, a guy who has developed a ton of influential packages for R.
- Reproducible Research: Many concepts for making research reproducible is covered in the previous two courses. This course adds the use of Markdown and Knitr (hello Daring Fireball). Markdown is a plain text language; Knitr is a package for creating documents that contain both text and executable code. At a high-level, it helps a researcher communicate and summarize their thoughts when performing an analysis.
- Statistical Inference: In 4 weeks, this course goes from nothing to bootstrapping. That is a good thing with R; it is not a good thing with statistics. Week 2 includes rate measurement and the Poisson distribution! In my opinion, it would be more helpful to find an introduction to statistics course - something that gets into the actual mathematics of the equations. It would be better to take time understanding how sampling relates to a population and how the Central Limit Theorem works instead of trying to use a t.test() in R as quickly as possible.
- Regression Models: This course is a high-level introduction to regression, which is one tool in the “DS toolkit.” It identifies how to use ANOVA tests, how t-tests work, and how to determine when results are statistically significant. I learned a lot about residual analysis from this course; namely how to plot different charts of the residuals to ensure that the regression captures as much of the “structure” of the data as possible (and that the residuals represent truly random information).
- Practical Machine Learning: There is too much information beyond regressions to lump into one course (e.g., dimensionality reduction, classification, clustering - and when different models work). These classes end up being an introduction to the caret() package and exercises in which random forests are the best answer. The final project was very interesting, though; I learned how to use a correlation plot ( cor() ) and more about principle component analysis (PCA), which I had heard of before, but not encountered.
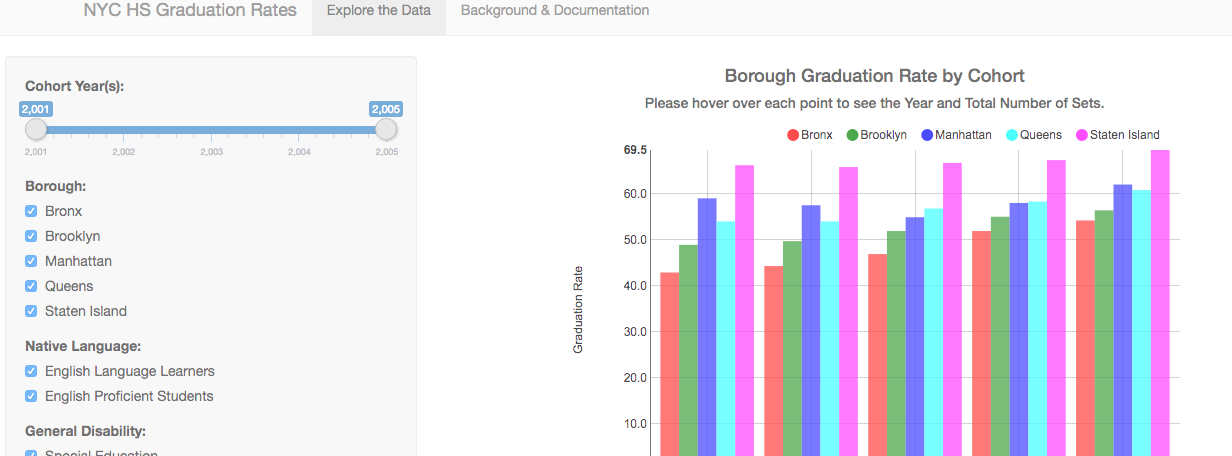
- Developing Data Products: This course was a great description for how Shiny works as a web application framework for R. I also really enjoyed the final project - I used data from the NYCDOE to explore graduation rates when I had been teaching. The only reason I am downgrading this as a course is that I will probably never use it professionally. I write more about this project here.
- Capstone Project: The Capstone project was a partnership with Swiftkey, a predictive text application. My project can be found here. You’ll find it does predict, but barely. :) In the background, I make a list of the things I would do differently provided I had more time.
The capstone is a good introduction to Natural Language Processing (NLP); it is not a good capstone for the course. It felt like it came out of left field. I needed to teach myself a significant amount of new concepts regarding n-grams, smoothing, Katz backoff models, and developing holdout data for text models. It was a lot more than the natural conclusion of the preceding nine courses. (Now that being said, I did learn a ton.)
##Benefits
Rereading these course summaries, I definitely learned a lot. It was great to have a few months of curated learning: with dedication, someone could feasibly go from nothing to data products in R. The course has also developed credibility: the certificate is apparently equivalent to 1-year of education by the NSA. I won’t be applying anytime soon, but I’ll take it. :)
##Challenges
Ultimately, the reason that I don’t recommend paying for the full course is it really is a challenge to validate learning. Three key reasons:
- Uneven Feedback: Everyone taking the class is presumably a novice - for example, I know I could have had better code, better structured my regressions, and done more with my NLP model. I got this feedback from my coworkers at SVDS, but it wasn’t present in my grading. Therefore, it is very hard to trust that I learned everything correctly.
- Uneven Course Pacing: Several courses don’t do much more than introduce packages or programs to download - they are tools. They don’t teach the techniques data scientists use to create inference, and as a result, don’t really facilitate personal learning. On the whole, this is not the case. At the same time, I am a little disappointed I spent $29 for a course that helps you download RStudio.
- Unclear Applications: Many of the projects are “problem statements” - that is, they seem designed to facilitate a specific goal (e.g., proficiency in ggplot2) but lack the broader context for me to say, “This is how I can use this at work!” Even the predictive text model capstone feels like a narrow domain problem - I work at a data science consultancy and few of my colleagues have experience with these techniques. It could be more generalizable.
##So, who is this course for?
Would I recommend this course? I would, with heavy qualifications. For example, I would not treat this as true knowledge - I would not recommend someone to take this course and then go build their own data products trusting they did everything correctly. However, if someone took this course with the support of a community of data scientists - then it is a great tool for getting advice and starting a conversation.
In fact, double points if you can get your employer to pay for it. For example, AT&T and Udacity recently partnered for “nanodegrees.” It would be AMAZING if this course was sponsored by a company making the transition to a digital business and wanted their employees to develop a cursory intuition about data products and services. (Note: I recognize the irony in highlighting something great Udacity does in a Coursera review - Coursera should do this!!)