
Even if your company has full stack data scientists, data science is still ultimately a team sport. There are business stakeholders, product managers, designers, members of the infrastructure team - all of whom may have input, questions, and dependencies on the data scientist’s work. Each of these individual members likely have different interests, experiences, responsibilities, and patterns for problem solving.
This diversity in perspective can be an asset, when harnessed effectively. However, if not actively managed, these perspectives can also be a huge source of miscommunication, misalignment, lack of trust, and frustration. Acknowledging this, I discourage the word “done” from my projects. Far too often, the phrase “it’s done” is accepted - when a quick review between the two parties will reveal different expectations about what “done” is supposed to mean. For example, if your data scientist says, “the model is done / ready,” do they mean:
- The code accurately describes the problem, and is written purely in scripts, or
- The code is functional and parametric, and accounts for common edge cases, or
- The code documented and tested, in a way that can transfer ownership, or
- The code is schedulable and optimized, in a way that can run in production
Depending on where the project is in development - any of these answers could be sufficient. The challenge is when differences exist between how the two parties interpret the message.
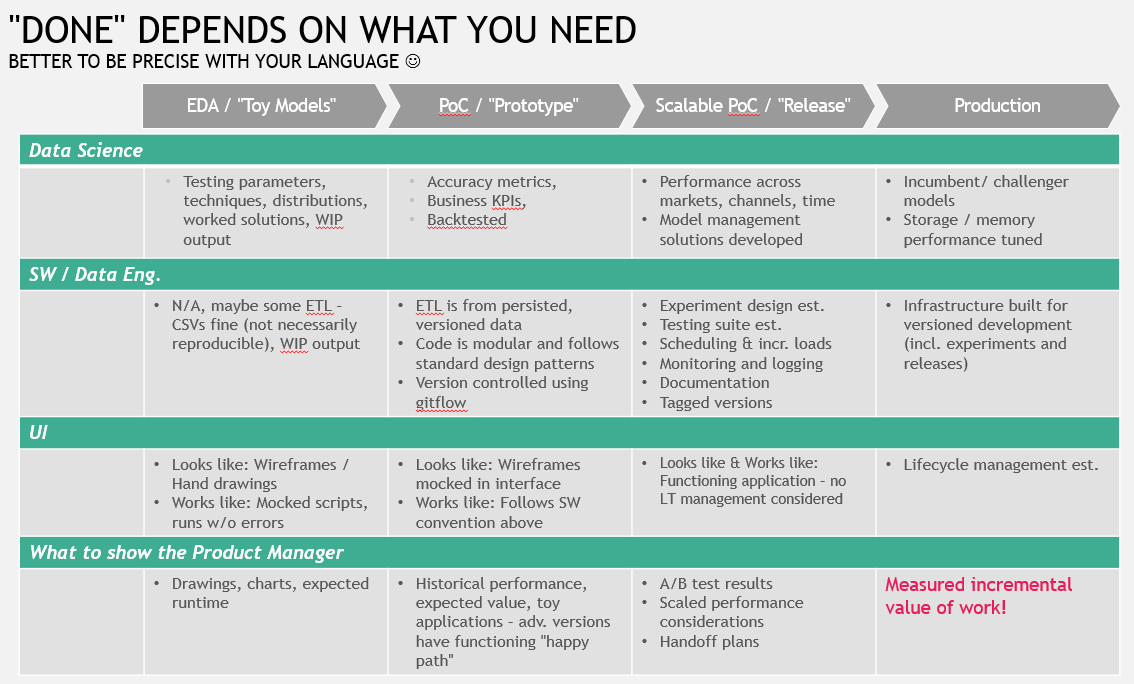
Best practices on removing the word “done” from your projects
- Empower the end user to own the logic: Sometimes, business users will treat the work of the data scientist as “magic.” This serves nobody - the model is not truly a “black box.” The code that dictates the inputs, the outputs, and the algorithmic approach is all logic. Sometimes the inference for a local prediction can’t be explained directly; that is a different topic than the overall problem design. Encourage conversation.
- Educate the end user on the work of model building and management: There is a lot of work to put models into production, and to maintain them once there - for example, with regard to drift, retraining, training/serving skew, security, maintenance, etc. End users should know they are investing in developing a system; the model is an artifact, not an end product, of that system.
- Foster a learning culture and growth mindsets: Most parties working on data science projects are on a learning journey together. There is a significant amount that is “new” - most data scientists learn through apprenticeship – which can create challenges for how to communicate effectively. Simply acknowledging this can make an important difference.
- Clearly articulate the tradeoffs with “good enough analysis”: In the data science workflow, it is easy to get stuck in a variety of local optima. For example, repeatedly asking for ad hoc analyses may give a greater intuition for the problem, while never giving the data scientist the time to professionalize her code. On the other hand, pushing for automation of a system may lead to too narrowly specifying the problem, eroding potential value. With software, there are real tradeoffs between flexibility and automation - and it is important to consider the appropriate balance for the system being defined.
When considering “done”, a large risk present in a “good enough analysis” culture is the potential to create technical debt. Technical debt often goes unrecognized until it is too late, creating unacknowledged costs that will eventually need to be paid down. Even with a high prevalence of ad hoc work, it is not an excuse for running an “unclean” process. Below, please find a few recommendations to “keep things clean.”
Tips for cleanliness in development:
- Use code spikes: Code spikes are a term from XP Programming that refer to code used to understand a problem rather than develop working code. For data science, I treat EDA as the same - and keep it out of /src within the codebase.
- Enforce a good PR process: Google has a wonderful guide for code reviewers. Key quote for me is, “Don’t accept PRs that degrade the code health of the system. Most systems become complex through many small changes that add up, so it’s important to prevent even small complexities in new changes.”
- Refactor and redesign as necessary: Clean code really pays off, and one should restructure the codebase as the problem definition changes. Here, it’s helpful to think about Martin Fowler’s YAGNI and Rule of Three.
Tips for cleanliness in sprint planning:
- Ensure Sprint Goals are output driven: Writing Sprint Goals are a bit of an art, needing to be both ambitious and achievable. As data scientists practice goal setting, watch out for task-oriented outcomes that make acceptance criteria less valuable and can lead to reduced productivity.
- Limit User Stories to 1-2 story points: Remember that story points are used to size work during sprints. They aren’t a tool to measure a developer’s productivity, and should not shouldn’t bleed across sprints.
- Create viable “Plan Bs”: Creating options is what makes Agile work work well. When building out “Agile tests” (prior post here), it is important to have credible alternatives for a path forward. Otherwise, the team won’t be managing risk - they’ll be rationalizing themselves towards a predefined outcome.
Good luck!
Hopefully after reading this, you’ll agree to the danger of using the word “done” in cross-functional teams. Fortunately, with awareness, there are many things that teams can do - in terms of both culture and process - that foster innovation and improve the likelihood of success in data science initiatives.