
Last month, I did the Data Weekends program - a 2-day machine learning workshop hosted by Francesco Mosconi. Francesco is a great leader for the program; he teaches at General Assembly and was also the Chief Data Officer for a Y-Combinator backed company, Spire. Basically.. he knows a “thing or two about a thing or two.”
For folks that might be thinking about doing the program, I wanted to share a bit of what a participant can expect to learn, some pros and cons, and things to consider when determining if it is right for you.
##Weekend Overview
Each day of the workshop went from 9am - 5pm and was a full day of activity. There was some lecturing to give context, but the time was spent predominantly interacting with python code to fully intuit the concepts and allow for questions. There were 8 of us in my workshop: some were data scientists, backend engineers, and co-founders of data start-ups. I paired with a woman named Vanessa who was a backend engineer for Rdio / Pandora. She was super helpful as I felt like I had a good grasp on the concepts, but needed more help with the programming.
The instructor starts by working through a few examples of practical applications of machine learning: instances in which regression, classification, clustering, or dimensionality reduction might be used. He then showed us how these techniques match well to the type of data being collected and the kind of problem one wants to solve. It came together in an easy framework:
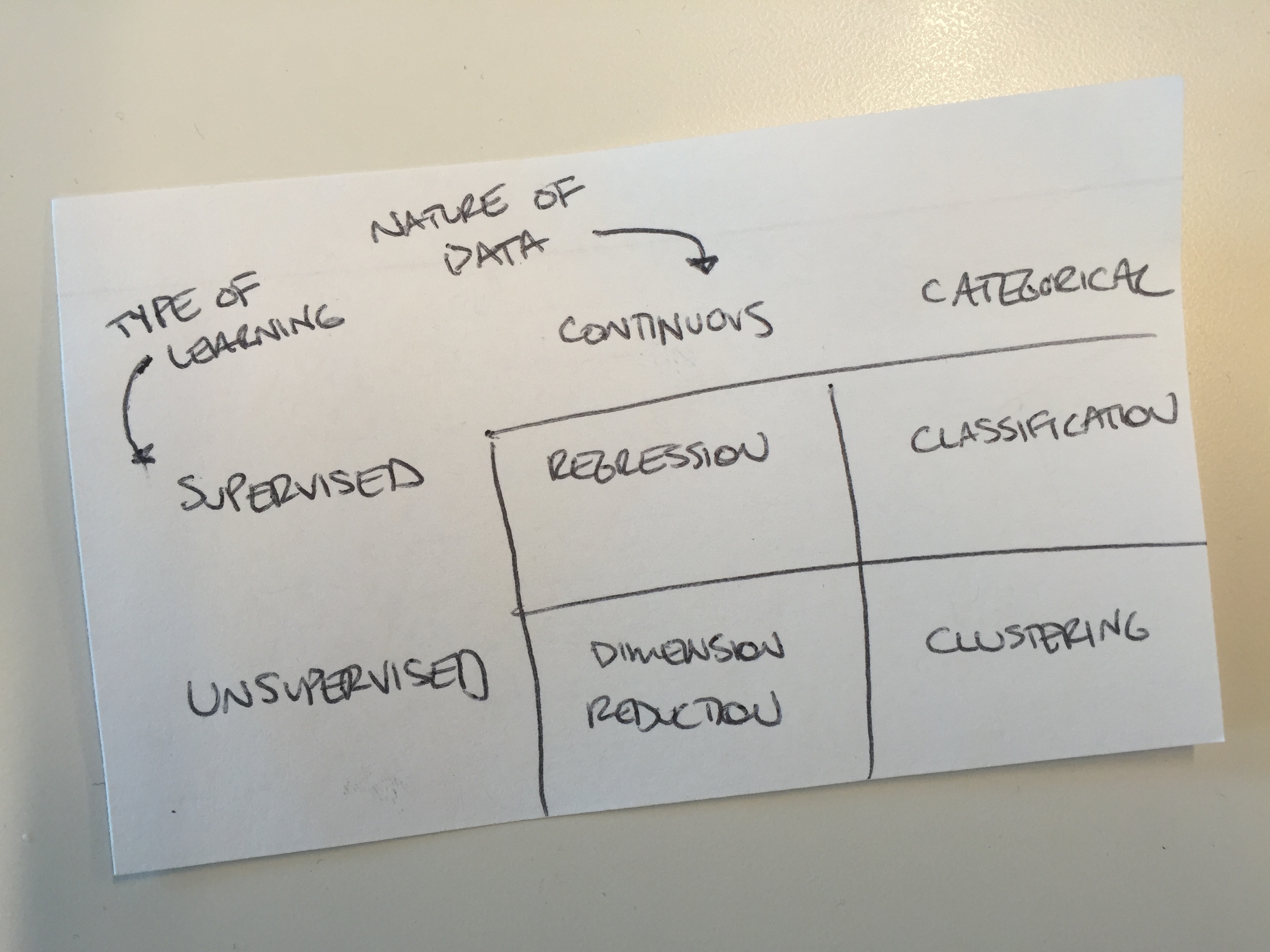
We then worked through modules for each section, with specific call-outs for cleaning data, and improving accuracy. The instructor uses pre-built Jupyter notebooks to help the participants grapple with the problems; we then can work with our partners to solve them, and, when stuck, get the instructor’s guidance.
The topics are meaty and move quickly; we discuss cost-functions and overfitting in statistics and work through how the cost-function is calculated differently for a sum-of-squares method vs. a support vector machine (SVM). We also gain a familiarity using different functions in the scikit-learn and pandas packages.
from sklearn.cluster import KMeansX = df[['sepal_length_cm','sepal_width_cm','petal_length_cm','petal_width_cm']]# look for 3 clusterskm = KMeans(3)km.fit(X)# try changing the initialization parameters of KMeans to 'random'. What happens?
Example code and discussion.
For each module, the instructor allowed for good discussion around the underlying intuition of the most popular machine learning models, and the types of problems in which each are best suited. To accommodate the varying levels of proficiency within the room, we also had access to more “advanced” iPython notebooks that operated as standalone guided instruction.
At the end of the two days, we built a simple web application using Heroku and Flask that is designed to do language prediction. The underlying model takes a few scraped text corpora from Wikipedia home pages for several languages (eg. English, Italian, French, Russian). We then vectorize those set of words into 3-character n-grams and create test and holdout sets. The goal of the model is to predict the language based on the probability that a vectorized string of text matches the n-grams for a given language in the database.
After testing a few different models, I found the highest accuracy for the SGDClassifier() in the scikit-learn package. You can find my Language Predictor here!
##Benefits
There were quite a few things I really enjoyed about Data Weekends:
- Great Conceptual Model: I found the instructor’s work to be a great blend of programming, statistics, and real world examples. With this, the overarching framework / conceptual model helped me understand when to apply different techniques and why. I had many similar concepts in a statistics class at Stanford, but I had trouble rooting that learning in something practical - this class actually gave me confidence to use things I had learned elsewhere as well!
- Pair Programming: I really enjoyed being paired with someone who was a professional software engineer. My goal is to work with an engineering team, and Vanessa was really kind and patient with my syntax questions. Hopefully, I was of some help with the statistics.
- Guided Jupyter Notebooks: Pre-built Jupyter notebooks were helpful for understanding “what we were working towards.” For learning exercises, we could get a sense of what we were going to cover end-to-end and what knowledge was being built. At the same time, since none of the code was executed - we could guess how models would perform, test them, and get feedback immediately.
- Advanced Sessions: Once we developed a basic intuition, the instructor would push us to get a better sense of how K-Means clustering works: for example, by changing the number of nodes, or dictating where calculations start from. Or to discuss the differences between Ridge and LASSO regressions. We also had notebooks for these sections.
- Focus on Practical Application: More than any online course, I appreciated the direct feedback from someone with practical experience in the field. I also appreciated that these activities were always connected back to how they could be used in the real world, and that we were given the opportunity to stage an environment and host an application - soup-to-nuts development.
##Challenges
This doesn’t mean that Data Weekends is for everyone, though - there are a few things based on the structure that may make the course challenging for others:
- Uneven Skills: First, data science and machine learning are nascent fields - and therefore the backgrounds of people trying to develop these skills are pretty diverse. For me, there were times in the class in which it felt like it was moving too slow or too fast. The same was true for others, but at different times.
- Big Time Commitment: Saturday and Sunday 9am-5pm is a pretty heavy commitment - an entire weekend spent exhausting your brain. Not only does it limit what you can do with your weekend nights, it also doesn’t necessarily leave you recharged for Monday morning. Energy levels are something to consider - and we definitely got tired even during the lectures themselves.
- Presumed Knowledge: The course moves pretty quickly through statistics and programming to the applications. I would say, in retrospect, that my python was not as good as it could have been to make the most of the class (I did LPTHW, Google’s Python Tutorial, and a pandas tutorial beforehand.)
##So, Who is Data Weekends For?
Data Weekends was great and I would wholeheartedly recommend it. That being said, it is certainly not for everyone. Perhaps someone who is an “advanced beginner” in programming and statistics: maybe with one Coursera course in each under their belt.
For the price, I would also recommend that a participant have a clear sense of how they’ll use the material professionally. I am not sure that the program would help someone get a new job, but it definitely can help a transition within a company and can help someone get a better sense of what is possible, technically speaking. Since I’ve just started to work for a data science consulting firm, I felt like the education helped me get a better sense of how I can be a better partner to the folks I work with.
Good luck! If you are considering taking this program, feel free to reach out to me at anytime to talk about it.